
Merging Multiple Git Repositories Into A Mono-Repo with PowerShell (Part 2)



Background
Following on from Part 1 where I give the background as to the reasons that I wanted to move to a single Git repository (also known as a mono-repo), this post provides a walk-through of the PowerShell script that I created to do the job.
The full script can be found at on GitHub in the MigrateToGitMonoRepo repository. The script make use of three 'dummy' repos that I have also created there. In addition, it also shows how to include repositories from other URLs by pulling in an archived Microsoft repository for MS-DOS.
Before Running the Script
There are a few things to be aware of when considering using the script.
The first is that I am neither a PowerShell nor Git expert. The script has been put together to achieve a goal I had and has been shared in the hope that it may be of use to other people (even if it is just my future self). I am sure there are more elegant ways of using both these tools, but the aim here was to get the job done as it is a 'one-off' process. Please feel free to fork the script and change it as much as you want for your own needs with my blessing.
The second thing to know is that the Git command line writes information to StdErr and therefore, when running, a lot of Git information will appear in red. All this 'noise' does make it hard to identify genuine errors. To this end, when developing and running the script, I used the PowerShell ISE to add breakpoints and step through the execution of code so I could spot when things were going wrong.
The last thing to be aware of is that there is no error handling within the script. For example, if a repo can't be found or a branch specified for merging is not present, you may have unexpected results of empty temporary directories being rolled forward and then appearing as errors when Git tries to move and rename those directories.
With this said, the rest of the post will focus on how to use the script and some things I learnt along the way while writing it.
Initialising Variables
At the start of the script there are a number of variables that you will need to set.
The $GitTargetRoot and $GitTargetFolder refer to the file system directory structure. You may not want to have a double nested directory structure you can override this further down in the script. The reason I did this is that I like to have a single root for all my Git repos on the file system (C:\Git) and then a directory per repo under this.
The $GitArchiveFolder and $GitArchiveTags will be used as part of the paths in the target repo to respectively group all the existing branches and existing tags together so that there is less 'noise' when navigating to branches and tags created post-merge.
If all the existing repositories have the same root URL it can be set in the $originRoot variable. This can be overridden later on in the script to bring in repositories from disparate sources (in the script example, we pull in the MS-DOS archive repository from Microsoft's GitHub account).
While the merge is in progress, it is important to avoid clashes with directory names on the file system and branch names in Git.
The $newMergeTarget and $TempFolderPrefix are used for the purpose of creating non-clashing versions of these. There is a clean up at the end of the script to rename temporary folders on the file system. The script does not automatically rename the target branch as this should be a manual process after the merge when ready to push to a new origin.
Define the Source Repositories and Merge Behaviour
The next stage in the script is to define all the existing repositories that you want to merge into a single repository. To keep the script agnostic in terms of PowerShell versions, I have used the pscustomobject type instead of using classes (supported from PowerShell 5 onwards).
In each entry, the following values should be set:
originRoot is usually left as an empty string to indicate that the root specified globally at the start of the script should be used. In the example, the last entry demonstrates pulling in a repo from a different origin.
repo is the repository within the origin. In the example I have three dummy repositories that I have created in my GitHub account that can be used as a trial run to get used to the script works before embarking on using your own repositories.
folder is the file system directory that the contents of the repository will be moved to once the migration is complete. This is used to ensure that there are no clashes between directories of the same name within different repositories. You are free to change how the overall hierarchy is structured once the migration is complete.
subDirectory is usually an empty string, but if you have several repositories that are you want to logically group together in the file system hierarchy, you can set folder to the same value, E.g. Archived and then use subDirectory to then define the target for each repo under that common area.
mergeBranch is the branch in the source repository that you want to merge into the common branch specified in $newMergeTarget. In most cases, this will be your 'live' branch with a name like main, master, develop or build. If left as an empty string, the repository will be included in the new mono-repo, but will effectively be orphaned into the archive branches and tags.
In my real-world case , the team had a few repositories that were created and had code committed, but the code never went anywhere, so not needed in the new main branch. However, we still want access to the contents for reference.
tempFolder is a belt-and-braces effort to ensure that there are no folder clashes if the new folder name in folder happens to exist in another repository while merging. The value here will be appended to the global $TempFolderPrefix with the intention of creating a unique directory name.
File System Clean Up
Before getting into the main process loop, the script does some cleaning up to ensure that previous runs of the script are deleted from the file system to ensure a clean run. You may want to change this if you want to compare results so that previous runs are archived by renaming the folder .
Once cleaned up, a new Git repository is created and an initial commit is created in the new branch. This is required so that Git merges can take place herein.
The Main Loop
With the array of source metadata created, we move into the main loop. I won't go into a line by line breakdown here, but instead give an overview of the process.
The first thing to do for each repository is to set it as an origin and pull down all the branches to the file system. An important thing to note about the Git Pull is the --allow-unrelated-histories switch. Without this, Git will complain about no common histories to be able to merge.
As as aside, if your source repository is large, this may take some time. When developing the script, I thought something had gone wrong - it hadn't - it was just slow.
With that done, we can then enter a loop of iterating through each branch and checking it out to its new branch name in the new repository (in effect, performing a logical move of the branch into an archive branch, but really this is just using branch naming conventions to create a logical hierarchy).
You may notice some pattern matching going on in this area of the script. The reason for this is that the Git branch -r command to list all the remote branches includes a line indicating where the orgin/HEAD is pointing. We do not need this as we are only interested in the actual branch names.
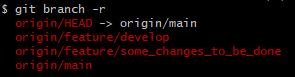
Once all the branches have been checked out and renamed, we return back to our common branch and remote the remote.
At this point, if we have specified a branch to merge into our common branch, the script will then
- merge the specified branch, again using the --allow-unrelated-histories switch to let Git know that the merge has no common history to work with
- create a temporary folder (as defined in the array of metadata) in the common branch
- move the complete contents of the branch to that temporary folder
Care is needed in this last step once we have performed the first merge as the common folder will include previously merged repositories in their temporary folders. Therefore, to avoid these temporary folders being moved, we build up a list of the temporary folders we have created on each iteration and them to the exclude list that is fed into the Git mv command.
At this point, an error can creep in if the branch name specified in the item metadata does not exist in the source repository. When writing the script I received Git errors indicating there were no files to move and ended up with empty temporary folders littered around the new repository.
Again, you may choose to put some error handling in or, on the other hand, just correct the branch name and repeat the process from the start again.
Before moving to the next item in the metadata array, the script copies all the tags to the the logical folder of tags specified in $GitArchiveTags.
The Post Migration Clean Up
Once the migration has completed, there is a bit of tidying up to do.
If you remember, to avoid clashes between directories while the migration takes place, we used temporary directory names. We now need to do a sweep through to rename those temporary directory names to the intended destination names.
At this point, we are ready with the final mono-repo.
If you have run the script 'as-is' using my demo values, when you look on your file system, it should like like this
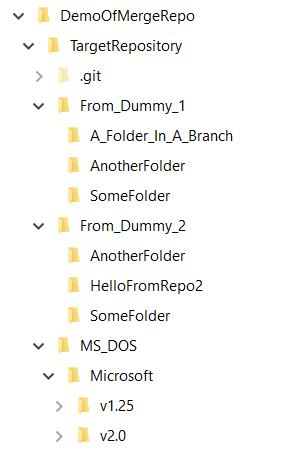
If you use a tool such as Atlassian SourceTree, you get a visual idea of what we have achieved with the merge process.

Before Pushing to a Remote
With our migrated repository, we are now almost ready to push it up to a remote (be it GitHub, Azure DevOps, BitBucket et al).
However, at this point you may want to do some tidying up of renaming the __RepoMigration branch to main.
The repository is now in a state where you are ready to push it to a remote 'as-is'. On the other hand, you may want to create an empty repository in the remote up front and then merge the migrated repository into it. If you do this, remember to use the # git pull --all --allow-unrelated-histories -v after adding the new remote.
At the end of the script, there is a commented out section that provides the commands I used to push up all the branches and tags created.
Alternatively, you may want to take manual control via the Git command line (or a GUI tool such as SourceTree).
Lessons Learnt
I have already mentioned earlier about problems with non-existent branches being specified, but there are other things to know.
My first piece of advice is to use the PowerShell Integrated Script Editor (ISE) to single step your way through the script using my dummy repositories to familiarise yourself with how the script works.
Once familiar, start with using one or two if your own repositories that are small and simple to migrate, to get a feel for how you want to merge branches into the new 'main' branch.
By single stepping, you will get instant feedback of errors occurring. As mentioned above, because Git writes to StdErr, it is hard to tease out the errors if running the script from start to finish.
Next, don't automate pushing the results to your remote until you are happy that there is nothing missing and that the merges specified meet how you want to take the repository forward.
If you use a tool like SourceTree, don't leave it running while the migration is taking place. Whilst it feels useful to graphically see what is happening while the script is running. it slows the process down and can in some cases cause the script to fail as files may become locked. Wait until the migration is complete and then open SourceTree to get a visual understanding of the changes made.
My last lesson is to have patience.
When I worked on this using real repositories, some of which had many years of histories, there are some heart-stopping moments when the repositories are being pulled down and it feels like something has gone wrong, but it hasn't - it's just Git doing its thing, albeit slowly!
Moving Forward
One of the downsides of mono-repos is size. In my real-world scenario that inspired this script and blog, the final migrated repo is 1.4GB in size. This is not massive compared to the likes of some well known mono-repos that are in the hundreds of gigabytes in size.
Once you have pushed the repository up to a remote, my advise is to clone the repo into a different local directory and only checkout the main branch (especially if you have a lot of orphaned archive branches that you don't need to pull).
If disk size is still an issue, it is worth looking at the Git Virtual File System to limit the files that are pulled down to your local system
Conclusion
I hope that the two posts and the script are of help to people.
There is a lot of debate about the relative merits of poly-repo vs. mono-repo that I haven't gone into. My view is to do what fits best and enables your team' to work with minimal friction.
The reason for the migration that inspired this post was having difficulties in coordinating a release for a distributed monolith that was spread across several repositories. If you have many repos that have very little to do with one another (being true microservices or completely unrelated projects), there is probably no benefit to moving to a mono-repo.
In summary, to use a well worn cliché, "it depends".